Baidu lansează ERNIE 5.1: primul loc între modelele chinezești, cost de antrenare de doar 6% față de rivali
ERNIE 5.1 comprimă parametrii la o treime față de predecesor, dar urcă pe locul 1 între modelele chinezești în Arena Search. Capabilități de agent, raționament și scriere creativă la nivel de top, la un cost de antrenare...

Ascultă Articolul
Voce Standard
Baidu a lansat oficial ERNIE 5.1, un model care moștenește fundația pre-antrenării lui ERNIE 5.0, dar comprimă parametrii totali la aproximativ o treime și parametrii activi la circa jumătate. Rezultatul: performanță de vârf la scară similară, cu un cost de pre-antrenare de doar 6% față de modele comparabile.
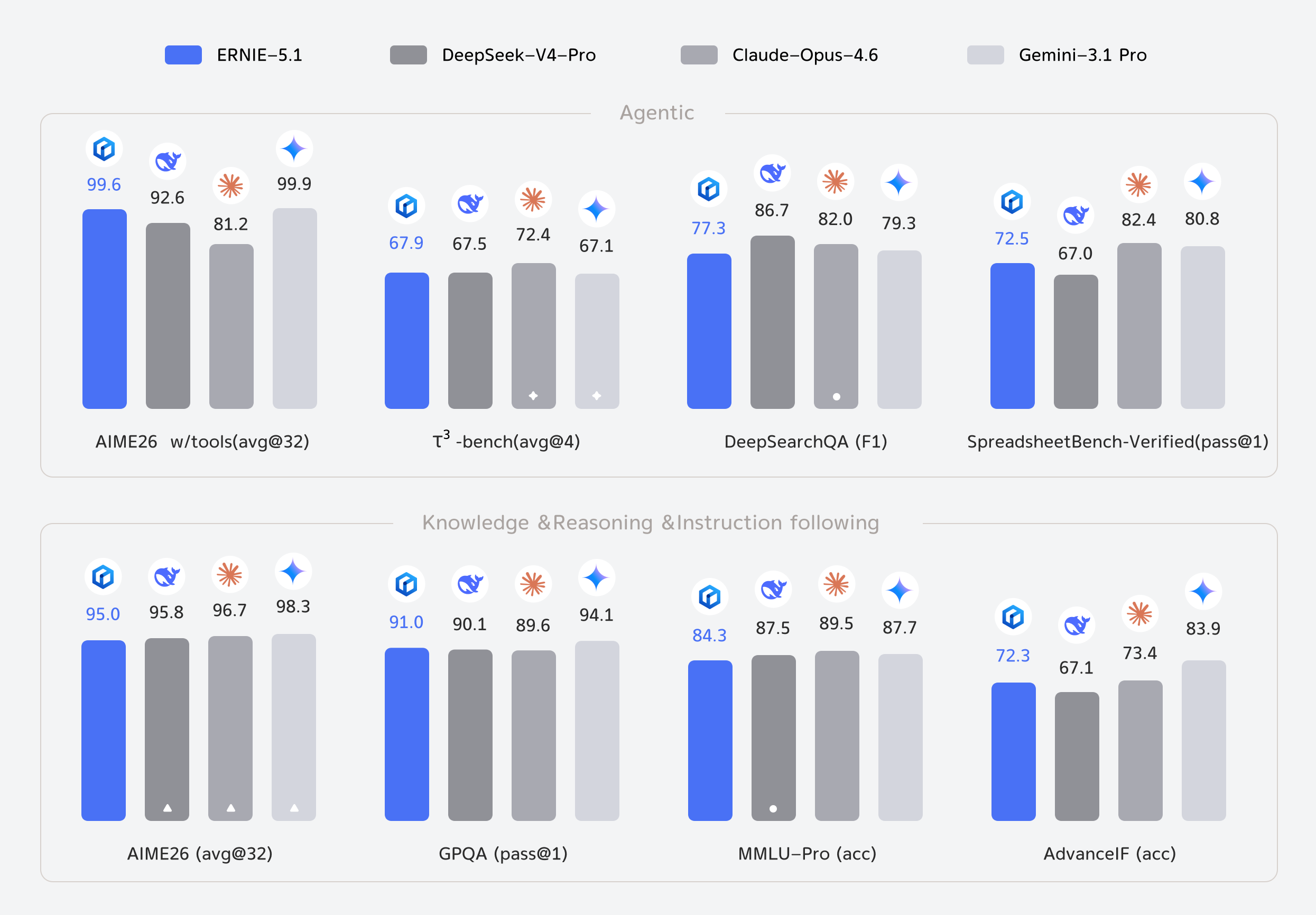
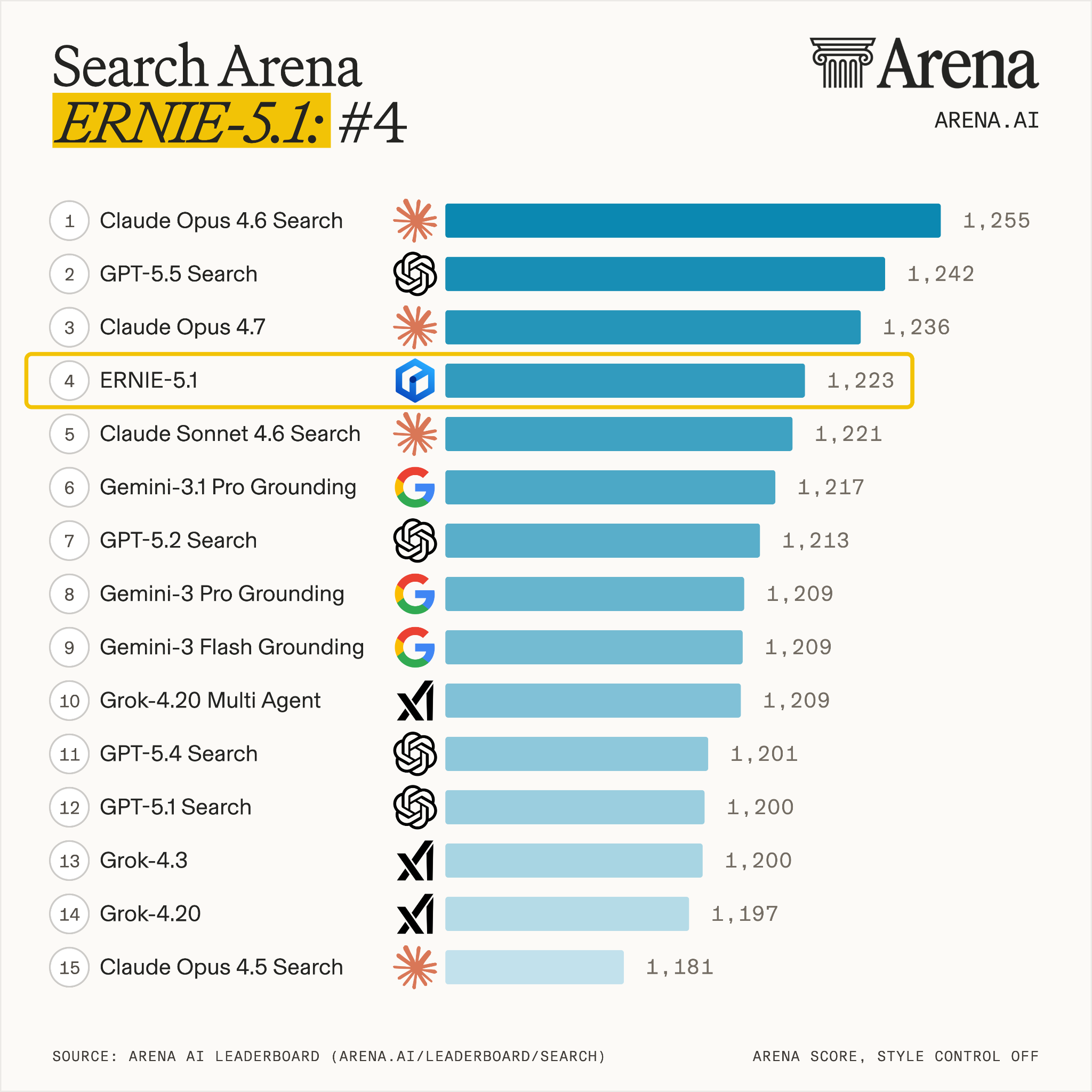
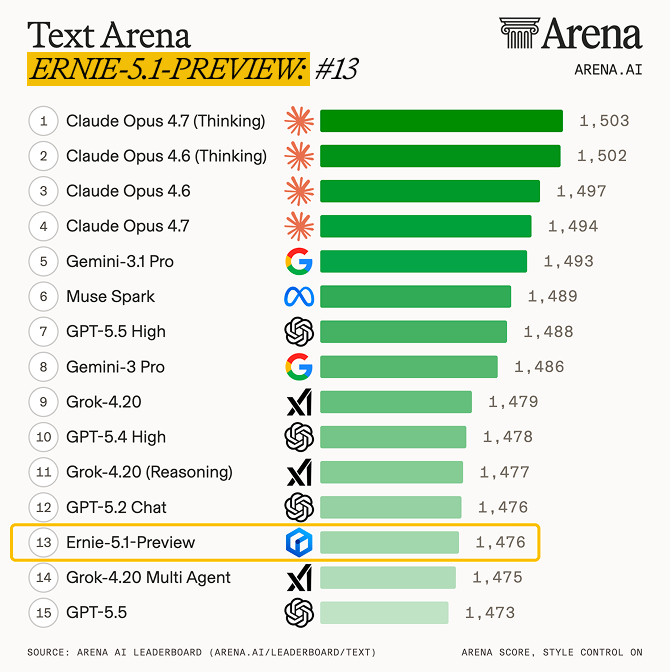
Poziționare în topurile internaționale Pe 9 mai, ERNIE 5.1 a obținut locul 4 global și locul 1 între modelele chinezești în clasamentul Arena Search. Modelul excelează în capabilități de agent (depășind DeepSeek-V4-Pro pe τ³-bench și SpreadsheetBench-Verified), raționament matematic (scor 99,6 pe AIME26, al doilea după Gemini 3.1 Pro) și scriere creativă (apropiindu-se de Gemini 3.1 Pro în evaluări interne).
Inovația tehnică: antrenament elastic multi-dimensional Baidu a dezvoltat un cadru de antrenament elastic „Once-For-All”, care optimizează simultan sute de sub-modele cu adâncimi, capacități de expert și niveluri de dispersie diferite într-o singură sesiune de pre-antrenare. Compresia se realizează pe trei dimensiuni: adâncime elastică (variază numărul de straturi Transformer active), lățime elastică (modulează capacitatea experților MoE) și dispersie elastică (ajustează flexibil numărul de experți activați prin rutare Top-k variabilă).
Infrastructură de învățare prin consolidare complet asincronă ERNIE 5.1 beneficiază de o arhitectură decuplată construită pe PaddlePaddle, care separă antrenamentul, inferența, recompensa și bucla de agent în patru subsisteme independente, scalabile autonom. Optimizările includ consistență FP8 antrenament-inferență (reducând divergența KL cu 50%) și programare elastică eterogenă a resurselor, care valorifică resursele CPU neutilizate din cluster.
Pipeline de post-antrenare în patru etape Baidu propune o abordare centrată pe Multi-Teacher On-Policy Distillation (MOPD): (1) SFT unificat pentru fundamentul instrucțiunilor, (2) antrenament paralel al experților pe domenii, (3) distilare on-policy pentru fuziunea capabilităților și (4) RL online general pentru scenarii conversaționale. Această separare elimină conflictele de optimizare multi-obiectiv și efectul de „balansoar” între capabilități.
Recunoaștere din partea industriei creative ERNIE 5.1 va fi disponibil pe peste zece platforme de creație, inclusiv ISEKAI ZERO și Storymaster. Companiile de conținut și scriitorii profesioniști îl consideră deja un model de referință care „înțelege utilizatorii, înțelege conținutul și înțelege contextul”.